
The real cost of cheap AI inference
The companies raising prices are the honest ones, and the ones keeping them low should worry you


Three AI providers raised their prices in February 2026, all within weeks of each other. Chutes killed its free tier on February 27th. Z.ai hiked by more than 30%, citing overwhelming demand. Synthetic bumped from $20 to $30 a month, tossing in 500 free tool calls as a sweetener.
The developer backlash was instant. Reddit threads lit up with complaints about greed, broken promises, bait-and-switch tactics. Some users migrated to cheaper Chinese providers. Others started self-hosting.
But the anger was pointed in the wrong direction.
The providers raising prices were the ones telling you the truth about what inference costs. The ones keeping prices low were telling you something else entirely. And if you’ve ever watched a venture-backed company burn cash to capture a market, you already know how that story ends.
February’s reckoning
Chutes AI runs serverless inference on the Bittensor network. It’s decentralised, open-source, and until recently, absurdly generous. Some users were getting up to 324 times the value of their subscription in pay-as-you-go equivalent, with even Base tier users extracting over 100x. That’s a charitable donation with extra steps.
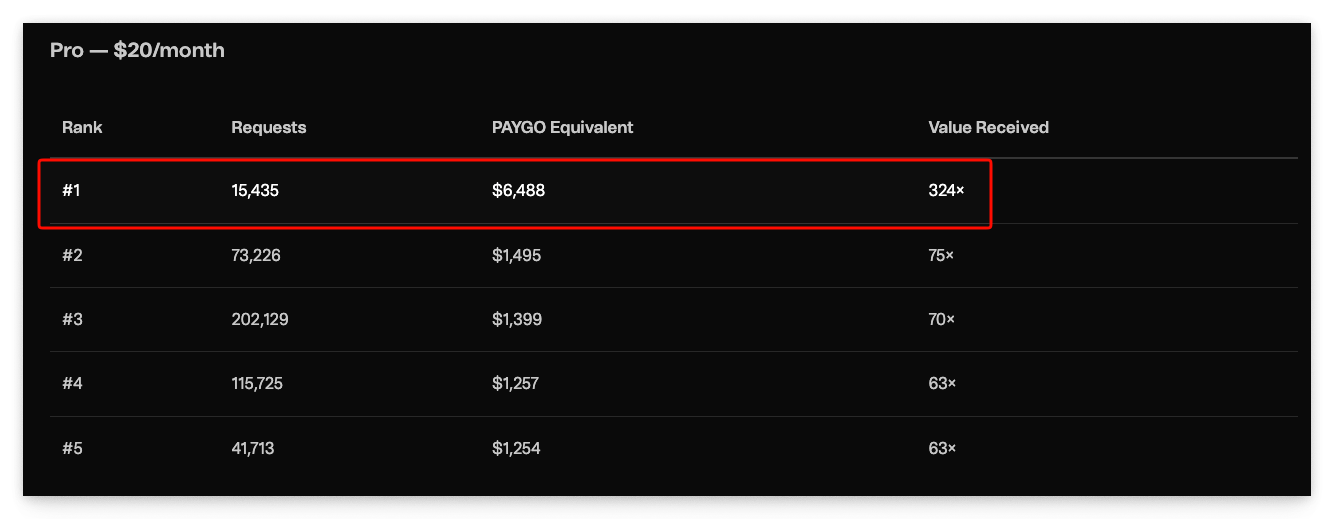
So Chutes did the uneasy thing. Killed the free tier. Capped subscriptions at five times their pay-as-you-go value. Pulled frontier models from the cheapest plan. The freeloader community response was predictable: fury, followed by cancellations.

Z.ai’s trajectory tells a starker story. Zhipu AI’s international platform started at roughly $6 a month. Then $30. Then $56. Reuters reported the latest hike on February 12th, attributing it to a “rapid increase in users.” Zhipu had just raised $558 million in a Hong Kong IPO. They could afford to subsidise users. They chose not to.
Synthetic went from $20 to $30, framing it as “$1 a day.” They added 500 free tool calls, expanded their model roster, and kept their privacy-first positioning: no data training, no prompt storage, GDPR compliance.
Of the three, Synthetic’s increase was the gentlest. Also the most honest about why it happened.
These price hikes aren’t cash grabs. They’re corrections. The introductory prices were never sustainable, and every provider knew it.
Synthetic’s Matt said:
We knew we were losing money on subscriptions, but this was okay when we were small: we hoped efficiencies of scale would turn us profitable when we became big. Unfortunately, we underestimated usage — and the popular open-source models got bigger and harder to run too, like Kimi K2.5. When we quadrupled in subscriber count, we realized our projections had been wrong: we needed to raise prices to just to stay afloat.
And let’s be honest: most of us would rather get honesty like the above than be lied to. Honesty’s a keeper.
Going back, nobody wanted to say it out loud, but the introductory prices were loss leaders. Every single one. The question was never whether they’d go up, but when.
What inference actually costs
Let’s talk about GPUs, because that’s where the money goes.
An Nvidia H100, the workhorse of current inference deployments, costs between $25,000 and $40,000 to buy outright. Cloud rental runs $1.49 to $6.98 per hour depending on the provider and commitment level. An H200 sits in a similar purchase range but pulls more power. The next-gen B200 pushes both costs higher.
Those numbers are per card. One H100 running 24/7 for a month at mid-range cloud pricing (call it $3.50/hour) costs $2,520 in compute alone. Buy the card outright and amortise over three years (a generous lifespan given how fast GPU generations move), and that’s roughly $830 to $1,110 per month in hardware depreciation. Before the machine draws a single watt.

But the GPU is only the start of the bill.
Electricity runs $0.10 to $0.15 per kilowatt-hour in most US data centre markets. An H100 draws about 700 watts under load. Running one around the clock costs roughly $50 to $75 per month in raw electricity. Scale that to a cluster of 64 cards (a modest deployment for a multi-model provider) and you’re looking at $3,200 to $4,800 per month in power alone. That’s before cooling, which typically adds 30-40% to the electricity bill. GPU clusters run hot. There’s a reason data centres in Iceland and northern Sweden are suddenly popular. Cold ambient air is free cooling.
Network egress is the cost nobody talks about until they get the bill. Serving tokens to thousands of concurrent users means shipping data out of your infrastructure. Cloud providers charge $0.05 to $0.12 per gigabyte of egress. A busy inference API serving millions of requests per day can rack up thousands in bandwidth costs monthly.
Model loading and idle capacity eat money invisibly. A 70-billion parameter model in FP16 needs around 140GB of GPU memory just to load the weights. That’s two H100s (80GB each) holding a single model before it generates one token. If you’re offering 67+ models like Chutes does, you either keep popular models hot (expensive; those GPUs can’t do anything else) or swap models in and out on demand (slow; loading 140GB of weights takes time). Either way, you’re paying for capacity that sits idle between requests.
Engineering salaries round out the bill. Someone has to maintain the infrastructure, optimise batching strategies, handle failovers, monitor quality. A small inference team of five to eight engineers in a major tech market costs $1 million to $2 million per year.

Now the per-token maths. An H100 running a 70B parameter model in FP16 generates roughly 30 to 80 tokens per second depending on batch size, quantisation, and optimisation. Take the middle: 50 tokens per second. At $3.50 per hour in cloud costs, that’s about $0.019 per thousand tokens. Add electricity, cooling, bandwidth, amortised engineering costs, and you’re closer to $0.025 to $0.04 per thousand output tokens. For a frontier model at full precision, higher still.
Self-hosting looks cheaper on paper. Buy H100s outright at $30,000 each, amortise over three years with electricity and cooling, and you’re at roughly $0.015 to $0.025 per thousand tokens. But that requires serious upfront capital, technical expertise to manage, and you eat the cost of idle capacity during off-peak hours. Self-hosting only makes economic sense if you’re running high, consistent volume.
When a provider offers you unlimited inference on frontier models for $3 a month, someone is paying the difference. If you can’t figure out who, it’s probably you, just not in the way you expect.
Now divide a $3 monthly subscription by even the cheapest per-token cost. At $0.015 per thousand tokens, $3 buys you 200,000 tokens, roughly 150,000 words of output. About one medium-length novel. Sounds generous until you realise a single coding agent session can burn through 50,000 to 100,000 tokens in an hour. Heavy users blow through that $3 in a day or two.
The maths doesn’t work. It never did.
The suspiciously cheap alternatives
Against that cost reality, consider Alibaba’s $3 coding plan.
Model Studio’s offering bundles Qwen3.5-Plus, GLM-5, Kimi K2.5, and MiniMax M2.5 for $3 a month. Generous rate limits too: 1,200 requests per five hours, 9,000 per week, 18,000 per month.
Read the fine print. The $3 lasts one month. Month two costs $5. From month three onward, it’s $10. Classic escalating intro pricing. The $3 isn’t a price. It’s a hook.
Z.ai pulled the same move at larger scale. Start at $6, capture users, build dependency, then hike to $56 once switching costs are high enough to keep people around. The price nearly ten-xed in under a year.

The Chinese price war and what’s fuelling it
The broader context makes individual pricing moves easier to read. DeepSeek trained its V3 model for roughly $5.58 million. US frontier models cost upward of $100 million. When your training bill is 95% lower, you can afford to price inference aggressively. And I mean aggressively.
DeepSeek R1 arrived at prices 90-95% cheaper than Western competitors. Nvidia lost $593 billion in market capitalisation in a single day, the largest one-day wipeout for any company in stock market history. Investors suddenly had to confront the possibility that inference might become a commodity faster than anyone predicted.
The resulting price war has been fierce to say the least. Alibaba slashed Qwen-VL-Max costs by 85% in December 2025, then cut Qwen3-Max by another 50% soon thereafter. Baidu made Ernie Bot entirely free in April 2025. Tencent entered with Hunyuan Turbo S priced at $0.11 per million input tokens. A million tokens is roughly 750,000 words of input. Eleven cents.
The per-token pricing gap between Chinese and Western providers has become almost absurd. Moonshot AI’s Kimi K2.5 charges $2.50 per million output tokens. Claude Sonnet 4.6 charges $15 for the same volume. Six times the price. Are you getting six times the quality? For some tasks, maybe. For autocompleting your React components, probably not.
Chinese AI users doubled to 515 million by mid-2025. China now has over 1,500 large language models, roughly 40% of the global total. That much competition doesn’t produce sustainable pricing. It produces a race to zero.
These aren’t sustainable prices. They’re battle prices. And battles have casualties.
The question hanging over all of it: who runs out of patience first, the companies burning cash or the venture investors funding the burn?
The quantisation question
Here’s a dirty secret of cheap inference: you might not be getting the model you think you’re getting.
Quantisation reduces a model’s numerical precision to make it faster and cheaper to run. Think of it like audio compression. A WAV file is full quality. An MP3 at 320kbps is nearly indistinguishable. At 128kbps, you start noticing. At 64kbps, your favourite song sounds like it’s being played through a phone speaker in a bathtub.

AI models work the same way. INT8 quantisation stays within 0.04% of BF16 baseline accuracy on MMLU-Pro benchmarks; essentially lossless. FP8 occupies a similar near-lossless tier while halving memory requirements. INT4 saves the most compute.
As most if not all providers don’t disclose their quantisation level, you’re trusting that the “DeepSeek V3” you’re hitting through a $3 API is the same model that scored well on benchmarks. But those benchmarks were run at full precision.

Community speculation about silent quantisation is everywhere on Reddit. Users report inconsistent quality between providers running ostensibly identical models. Some outputs are sharp and coherent. Others feel vaguely off, hard to pinpoint but unmistakable once you notice. (Honestly, the inconsistency alone should tell you something.)
It’s like ordering a premium single malt and getting it watered down. The glass looks right. The colour is close. But something’s missing, and the bar will never admit what they did.
The cheaper the provider, the stronger the incentive to quantise aggressively. When your margin on each request is measured in fractions of a cent, switching from FP16 to INT4 can halve your GPU requirements. That’s the difference between losing money and breaking even.
We’ve seen this movie before
The playbook isn’t new. Subsidise aggressively, capture the market, raise prices once customers are locked in. Venture capital has been running this play for two decades.

Uber and the $20 billion bonfire
Uber lost 58 cents on every single ride in 2018. In the first half of 2016 alone, losses hit $1.2 billion. Total losses since 2015 ran into the tens of billions. The strategy was blunt: price below cost, destroy taxi companies, achieve market dominance, then raise prices.
China was the most expensive theatre. Uber burned $1 billion a year there, paying drivers multiples of the actual fare just to build supply. A billion a year. Didi countered with the same playbook and deeper pockets. In August 2016, Uber surrendered, merging its Chinese operations into Didi in exchange for an 18% stake. Even retreat cost billions.
Amazon’s nappy war
Amazon went after Diapers.com with the calculated patience of a company that can afford to lose money forever. They launched “Amazon Mom” with Subscribe & Save pricing, selling Pampers for under $30 a pack when Diapers.com (owned by Quidsi) charged $45. Quidsi estimated it was losing $100 million per quarter trying to compete. They couldn’t. They sold to Amazon for $545 million in 2010.

And then Amazon shut Diapers.com down entirely in April 2017. Didn’t even run it. The acquisition was never about owning the company; it was about removing the competitor, absorbing its customer base, and salting the earth behind it.
The cloud wars of 2014
This one is the closest parallel to what’s happening in AI inference right now. In March 2014, Google slashed cloud prices by 32%. AWS responded within days. Microsoft followed with cuts of 27-65% across different services. Google introduced preemptible VMs at a fraction of standard pricing. Over the following six years, AWS cut prices 44 separate times.
The cuts attracted waves of new customers who built their entire infrastructure on cloud services. Then, gradually, prices stabilised. New pricing tiers appeared. Premium features carried premium costs. Reserved instance pricing replaced on-demand flexibility. By 2020, the big three controlled the market and monthly cloud bills had crept well above those loss-leader lows. If you were locked into AWS by then, you weren’t switching to save 15%. The migration cost alone would eat years of savings.

Didi’s pyrrhic victory
Didi merged with rival Kuaidi in 2015, creating a dominant ride-hailing giant. But dominance didn’t end the spending. In the first five months after the merger, Didi spent 270 million dollars on private-car subsidies alone. Drivers and riders were both being paid to use the platform.
Didi won the war. Then lost the peace. In 2022, China fined Didi 8 billion yuan (roughly $1.2 billion) for data security violations, following a crackdown triggered by Didi’s ill-advised New York IPO. Turns out market dominance in China comes with strings Western companies don’t always anticipate.
Every unsustainably cheap AI plan is a bet that you’ll be too dependent to leave when the real price arrives.
The pattern repeats. Subsidise to capture. Lock in through integration. Raise prices once alternatives have been starved out or customers are too embedded to migrate. The Chinese AI price war follows this script with one added wrinkle: state backing gives Chinese companies a longer runway than most venture-funded Western competitors. DeepSeek’s 90-95% discount isn’t charity. It’s a customer acquisition cost, and the investors behind it can afford to wait.
The question for anyone building on a $3 AI API isn’t whether the price will go up. It’s how much, and when, and whether you’ll have built enough of your workflow around it that migrating feels impossible.
The privacy trade-off
Price isn’t the only cost. When you route your prompts through a Chinese AI provider, your data enters a different legal jurisdiction, and the rules there don’t work like you might assume.
China’s Personal Information Protection Law (PIPL), enacted in 2021, looks like GDPR on the surface. Both require consent for data collection. Both impose restrictions on cross-border transfers. Both carry significant penalties for violations.
The similarities end there.
PIPL requires that data processing serve China’s national interest. GDPR exists to protect individual citizens. Those two goals conflict when Chinese and European data intersect. PIPL mandates cross-border security assessments for any data leaving China, creating a regulatory trap: data that enters Chinese infrastructure becomes harder to get out. And the EU has not recognised China as having “adequate” data protection under GDPR’s Article 45, meaning European companies using Chinese AI APIs face dual compliance obligations with no safe harbour between them.

Then there’s the National Intelligence Law of 2017. Article 7 is the one worth reading carefully: organisations and citizens shall support, assist, and cooperate with national intelligence work. Not “may.” Not “under certain circumstances.” Shall. If a Chinese AI provider is asked to hand over your prompts, they’ve got no legal mechanism to refuse. The law doesn’t include an exception for commercial inconvenience.
This isn’t theoretical. ByteDance’s Doubao AI Phone was blocked by WeChat over PIPL consent issues. Even Chinese tech giants trip over these data handling requirements. If domestic companies can’t get it right, foreign users routing sensitive data through Chinese APIs face an even murkier picture.

For individual developers mucking about with side projects, this might be an acceptable risk. But companies sending proprietary code, customer data, or strategic documents through a $3 API? Yeah, that’s a different calculation entirely. European companies face particular exposure: using a Chinese AI API to process EU citizen data without a lawful cross-border transfer mechanism could violate GDPR, regardless of whether the Chinese provider is PIPL-compliant.
The cheap API might also be training on your data. Most budget providers don’t offer contractual guarantees against it. By contrast, Synthetic explicitly promises no data training and no prompt storage. Chutes supports Trusted Execution Environments (TEEs) where even the infrastructure operator can’t see your inputs.
Privacy has a cost. The providers charging more for it are the ones actually providing it.
What honest pricing looks like
Strip away the outrage and look at what the “expensive” providers actually did in February 2026.
Chutes’ announcement I mentioned earlier that read more like an open-source project’s transparency report than a corporate pricing update. They showed actual usage data: specific users consuming 100-324x their subscription value in API calls. They broke down why the free tier was unsustainable, with numbers, not platitudes. They acknowledged some users would leave. Accepted the trade-off.
That level of transparency from a SaaS company is rare. Most providers raise prices with a vague email about “continuing to invest in the platform” and a buried effective date. Chutes showed its working.

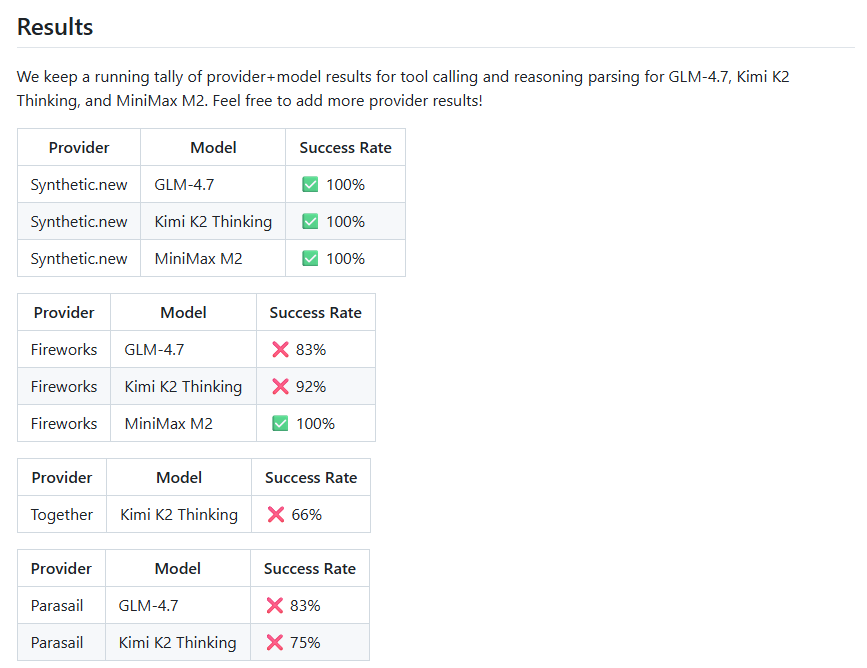
Synthetic took a different approach. Alongside its $10 price increase, Synthetic also increased maximum concurrency limits for higher tiers and continues to release new models, like GLM-4.7-Flash. More significantly, they built and open-sourced Synbad, an evaluation suite that tests whether AI providers actually serve the models they claim to serve.
Synbad scores Synthetic at a 100% pass rate compared to 66% on competing providers. If a third of model responses from other providers don’t match expected behaviour, silent quantisation or model substitution is the most likely explanation.
Building an evaluation tool that exposes your competitors’ quality issues is a bold move. It says: we’re confident enough in what we’re serving to give you the means to verify it. Budget providers making similar guarantees? None that I’ve found.
Z.ai cited user growth and cited it honestly. With a $558 million IPO war chest, they could have subsidised longer. They chose to price sustainably instead. Look, that’s not exciting. It doesn’t generate Reddit threads about generosity. But a company that prices for survival is a company that’ll still be around in two years.
The providers willing to show you the cost breakdown are the ones you should trust. The ones offering “unlimited” inference for the price of a coffee are hiding something in the margins.
Compare this to the $3 plans. No cost breakdowns. No explanation of how the pricing works. No disclosure of quantisation levels or data handling practices. No open-source evaluation tools. Just a price that’s too good to be true, offered by companies with the resources to absorb short-term losses indefinitely.
The cheapest option is rarely the cheapest option. The invoice just arrives later, in a currency you weren’t expecting: degraded quality, data exposure, vendor lock-in, or a sudden price hike once you’re too deep to walk away.

The invoice always arrives
Nobody runs AI inference at a loss because they love developers. Every suspiciously cheap plan has a business model behind it. Capture the market now, monetise later. Train on user data and sell the insights. Serve degraded models and hope nobody notices.

The February 2026 price hikes weren’t a betrayal. They were providers admitting what the GPU economics had been saying all along: inference costs real money, and someone has to pay for it.
The providers who raised prices chose you as the customer.
The ones who didn’t? They chose you as the product.
Liked this guide?
If you decide to try Synthetic, consider using my referral link below:
We both get subscription credit when you subscribe.
$10 credit for you, $10 credit for me.
It’s a nice way to say thanks if this article helped make a difference in your decision-making.
But honestly, just try it out for a few days and see the difference for yourself.
Can’t go wrong with that crowd.